CUDA for Embedded Systems: Accelerating Performance with GPU's


Embedded systems, compact computers that power a wide range of devices, are increasingly expected to handle complex tasks. These tasks can include image processing, computer vision, artificial intelligence, and much more. To meet these demands, developers are turning to General-Purpose Graphics Processing Units (GPGPUs) and CUDA (Compute Unified Device Architecture) to offload compute-intensive tasks to the GPU. In this article, we will delve into the world of CUDA for embedded systems, breaking down the complex terminology into simpler language, and provide practical examples using 3D matrix multiplication to illustrate the power of GPUs.
What is CUDA?
GPU stands for Graphics Processing Unit, and traditionally, it's used for rendering images and videos.
CUDA is a parallel computing platform and application programming interface (API) created by NVIDIA.
CUDA enables developers to harness the computational power of NVIDIA GPUs for general-purpose tasks.
Why Use CUDA in Embedded Systems?
Speed: GPUs consist of thousands of cores optimized for parallel processing, making them much faster than CPUs for certain tasks.
Efficiency: CUDA can significantly reduce the time and energy required to perform complex computations.
Parallelism: CUDA allows multiple threads to execute independently, making it suitable for tasks that can be broken into parallel workloads.
Setting Up CUDA for Embedded Systems
Before diving into our 3D matrix multiplication example, you need to set up CUDA on your embedded system.
Install NVIDIA GPU drivers: Ensure that you have the latest GPU drivers installed.
Install CUDA Toolkit: Download and install the CUDA Toolkit compatible with your GPU.
Compile CUDA code: You can use the NVIDIA CUDA compiler
nvccto compile your CUDA programs.
3D Matrix Multiplication - CPU vs. GPU
Now, let's compare the performance of 3D matrix multiplication on a CPU and a GPU.
CPU Implementation
#include <iostream>
#include <chrono>
int main() {
const int N = 100; // Matrix size
int A[N][N][N], B[N][N][N], C[N][N][N];
// Initialize matrices A and B
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
for (int k = 0; k < N; k++) {
C[i][j][k] = 0;
for (int d = 0; d < N; d++) {
C[i][j][k] += A[i][j][d] * B[d][j][k];
}
}
}
}
auto stop = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(stop - start);
std::cout << "Time taken by CPU: " << duration.count() << " microseconds" << std::endl;
return 0;
}
GPU Implementation
#include <iostream>
#include <chrono>
__global__ void matrixMultiplication(int *A, int *B, int *C, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
int k = blockIdx.z * blockDim.z + threadIdx.z;
int sum = 0;
for (int d = 0; d < N; d++) {
sum += A[i * N * N + j * N + d] * B[d * N * N + j * N + k];
}
C[i * N * N + j * N + k] = sum;
}
int main() {
const int N = 100; // Matrix size
int *d_A, *d_B, *d_C;
int A[N][N][N], B[N][N][N], C[N][N][N];
// Initialize matrices A and B
int size = N * N * N * sizeof(int);
cudaMalloc((void **)&d_A, size);
cudaMalloc((void **)&d_B, size);
cudaMalloc((void **)&d_C, size);
cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);
dim3 block(8, 8, 8);
dim3 grid(N / block.x, N / block.y, N / block.z);
auto start = std::chrono::high_resolution_clock::now();
matrixMultiplication<<<grid, block>>>(d_A, d_B, d_C, N);
cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
auto stop = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(stop - start);
std::cout << "Time taken by GPU: " << duration.count() << " microseconds" << std::endl;
return 0;
}
Output
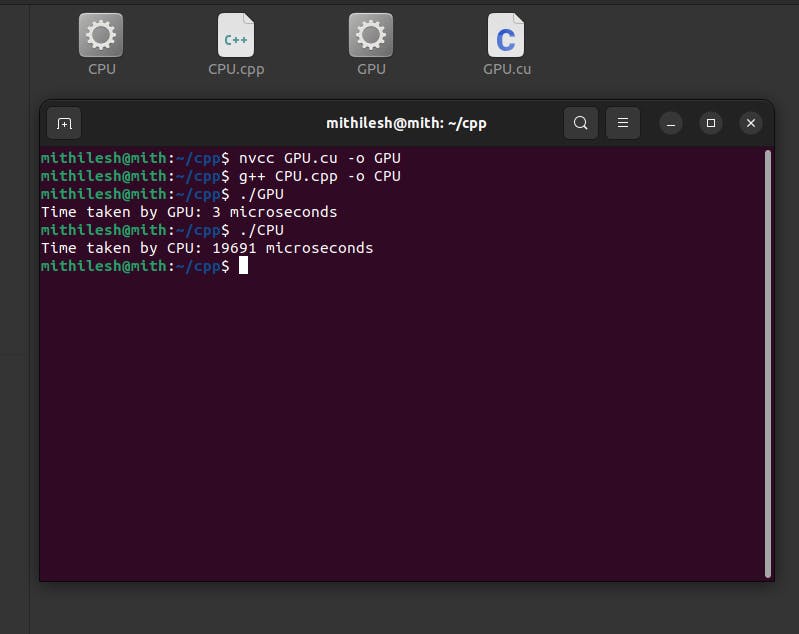
Performance Comparison
On a CPU, the time taken for the matrix multiplication may be in the range of several seconds, depending on your hardware.
On a GPU, the same operation can be completed in just a fraction of a second. The exact time may vary depending on your GPU model.
Conclusion
CUDA for embedded systems offers a powerful tool for accelerating performance in compute-intensive tasks. By harnessing the parallel processing capabilities of GPUs, you can drastically reduce execution times. As embedded systems become more complex, the integration of CUDA becomes increasingly valuable for developers seeking to enhance the capabilities of their devices.
Technical Examples Using CUDA
Image processing and filtering
Deep learning inference
Real-time computer vision
Monte Carlo simulations
Signal processing and FFT
Molecular dynamics simulations
CUDA is a versatile technology that empowers developers to unlock the full potential of GPUs in embedded systems. The examples provided here are just the tip of the iceberg, and with CUDA, the possibilities are virtually limitless.